Chapter 4 Sequential
#CSAPP
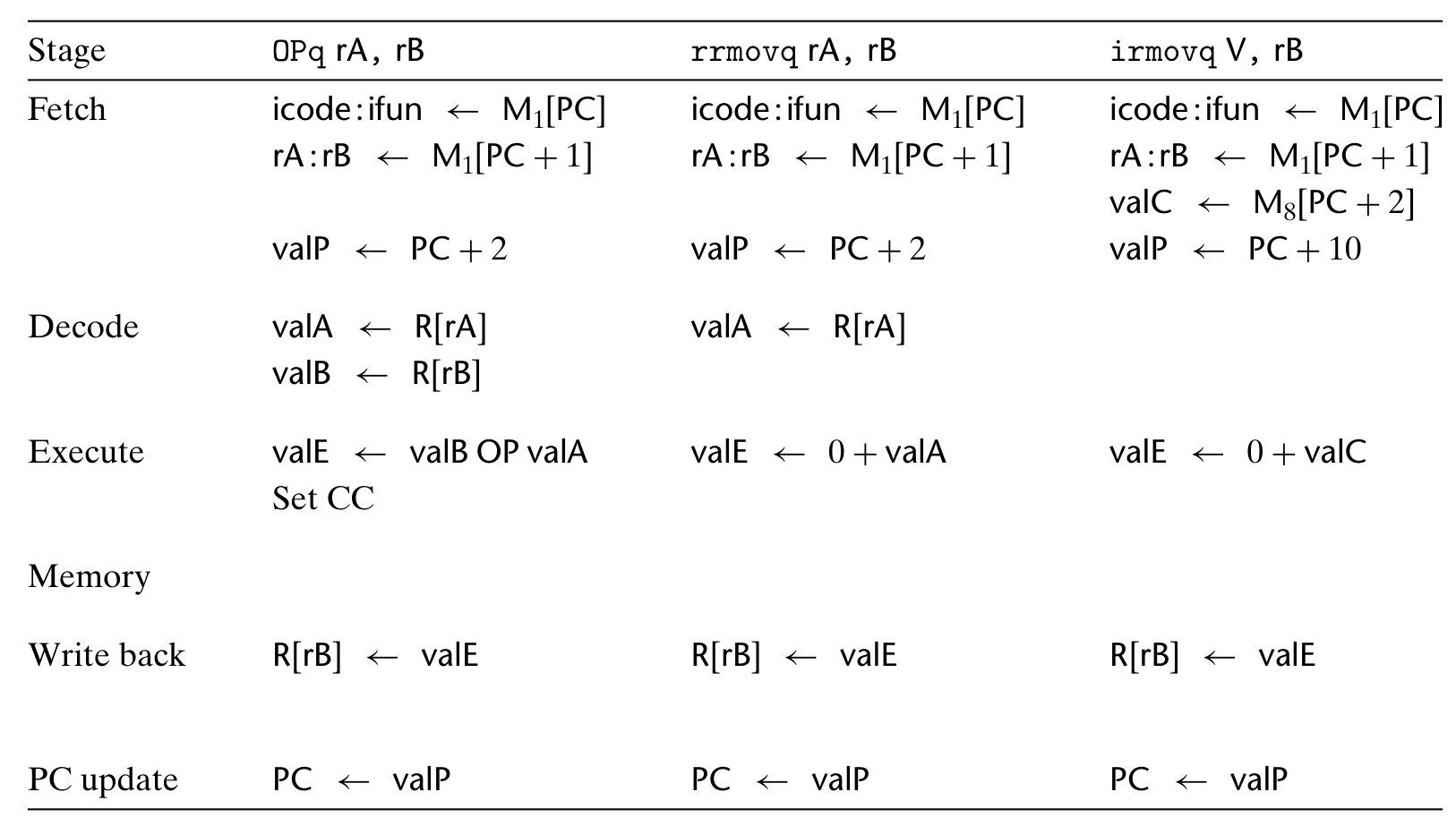
SEQ 处理器仅考虑一套简化的指令集,处理的所有数据对象均为 4 bytes 长,包括:
- 数据处理的:算数,包括加、减、位运算,操作数均为寄存器
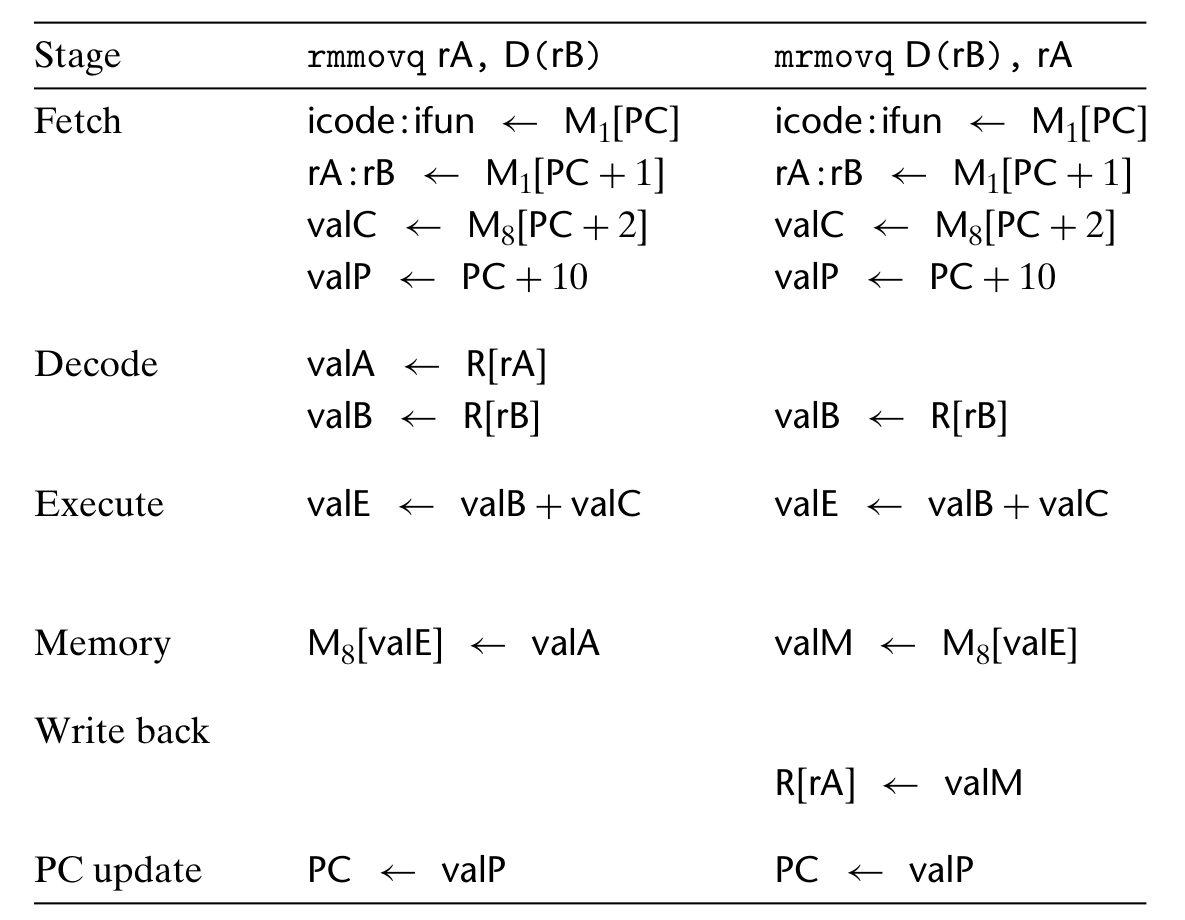
- 与内存交流数据的:数值移动,包括内存与寄存器之间、寄存器之间、立即数到寄存器的。不同的条件移动以 rrmovq 的不同 function code 表示。注意 SEQ 不支持 immovq,mmmovq。
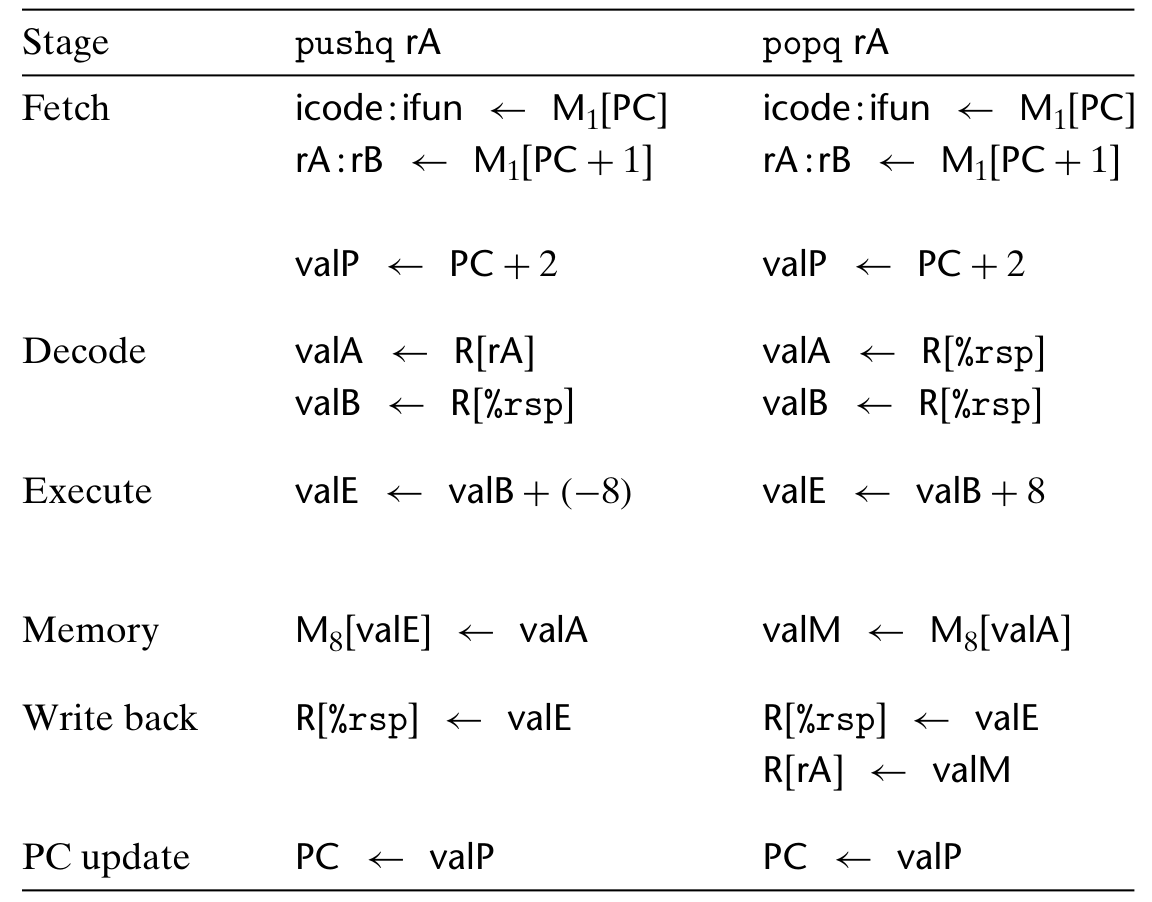
- 与内存交流数据的:寄存器与栈之间的 push 和 pop。注意 push 指令实际上是可以由
rmmovq %rA, -8(%rsp)和subq $8, %rsp组合而成的,不过组合指令会多消耗一个时钟周期,pop 类似。 - 控制执行过程的:
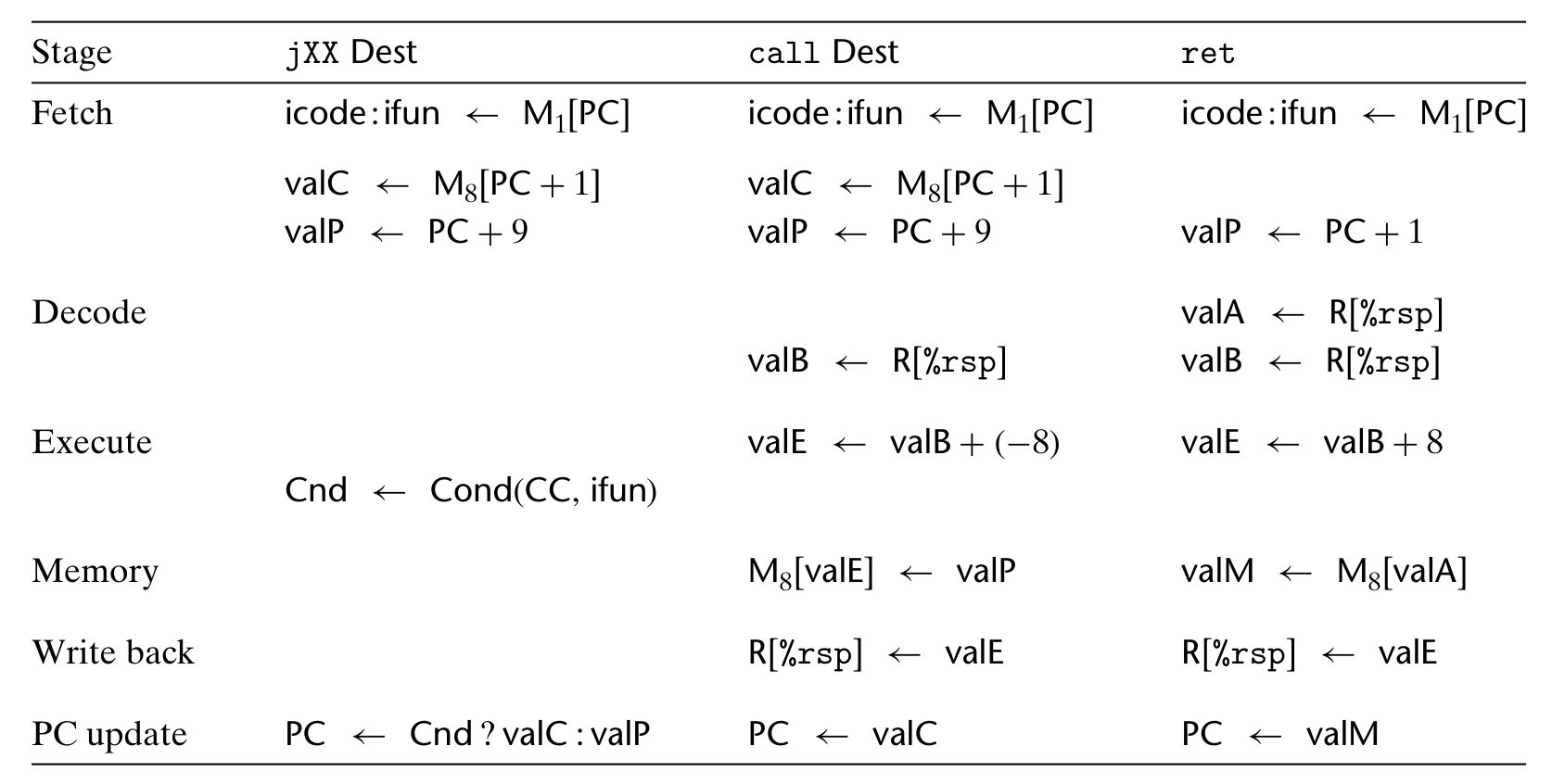
- (条件)跳跃指令,只支持绝对地址跳跃;
- 调用、返回指令。注意调用指令在 SEQ 上是可以由
irmovq $nextinstraddr, %rC,rmmovq %rC, -8(%rsp)和subq $8, %rsp组合而成的,会多消耗两个时钟周期,返回指令类似。可以把跳跃指令视作立即数到 PC register 的条件移动

uniform stage:
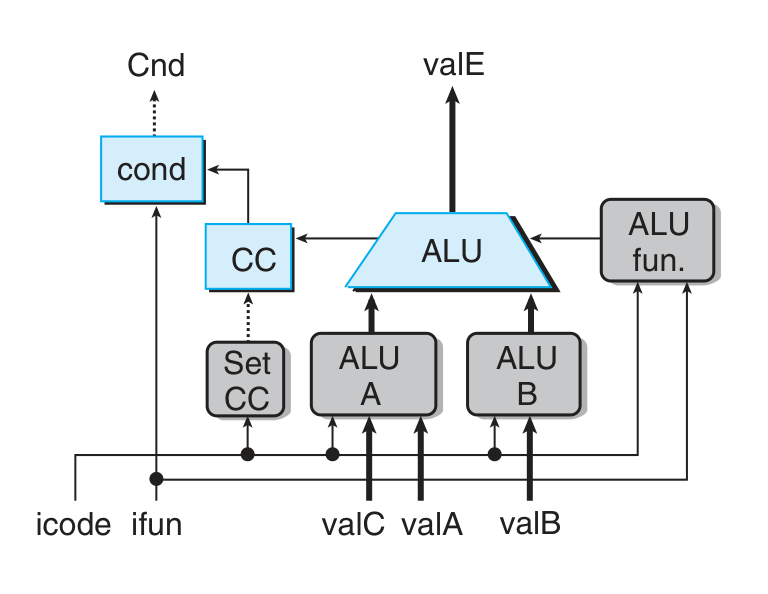
execute:
- rrmovq 中 valE = valA + 0 作为 ALU 的 nop,irmovq 中 valE = 0 + valC 作为 ALU 的 nop
- rmmovq / mrmovq (注意后者的寄存器顺序)中 ALU 计算 effective address valE = valC + valB
- pushq 和 callq 中计算 valB(R[%rsp]) - 8,作为储存地址
- popq 和 callq 中计算 valB(R[%rsp]) + 8,作为取回地址
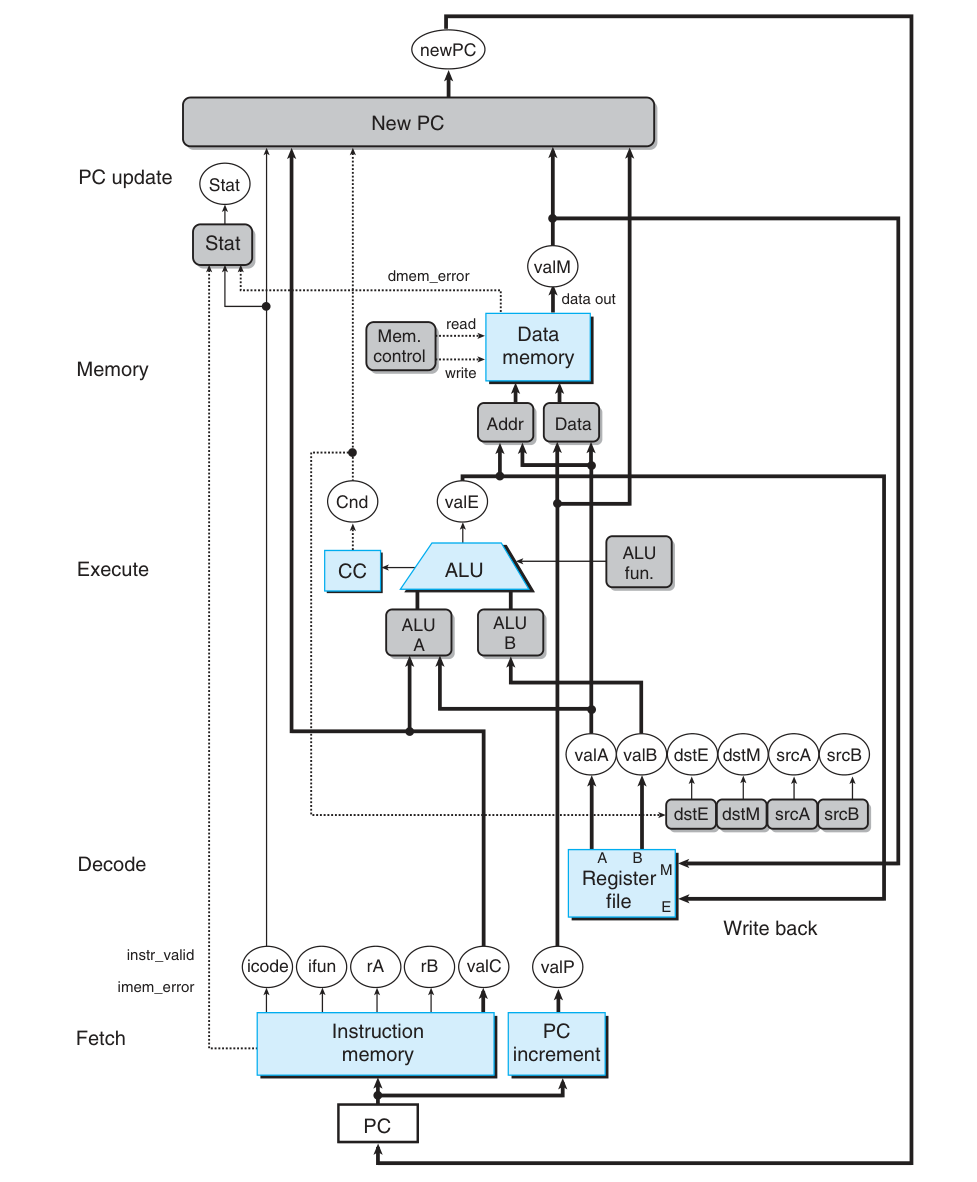
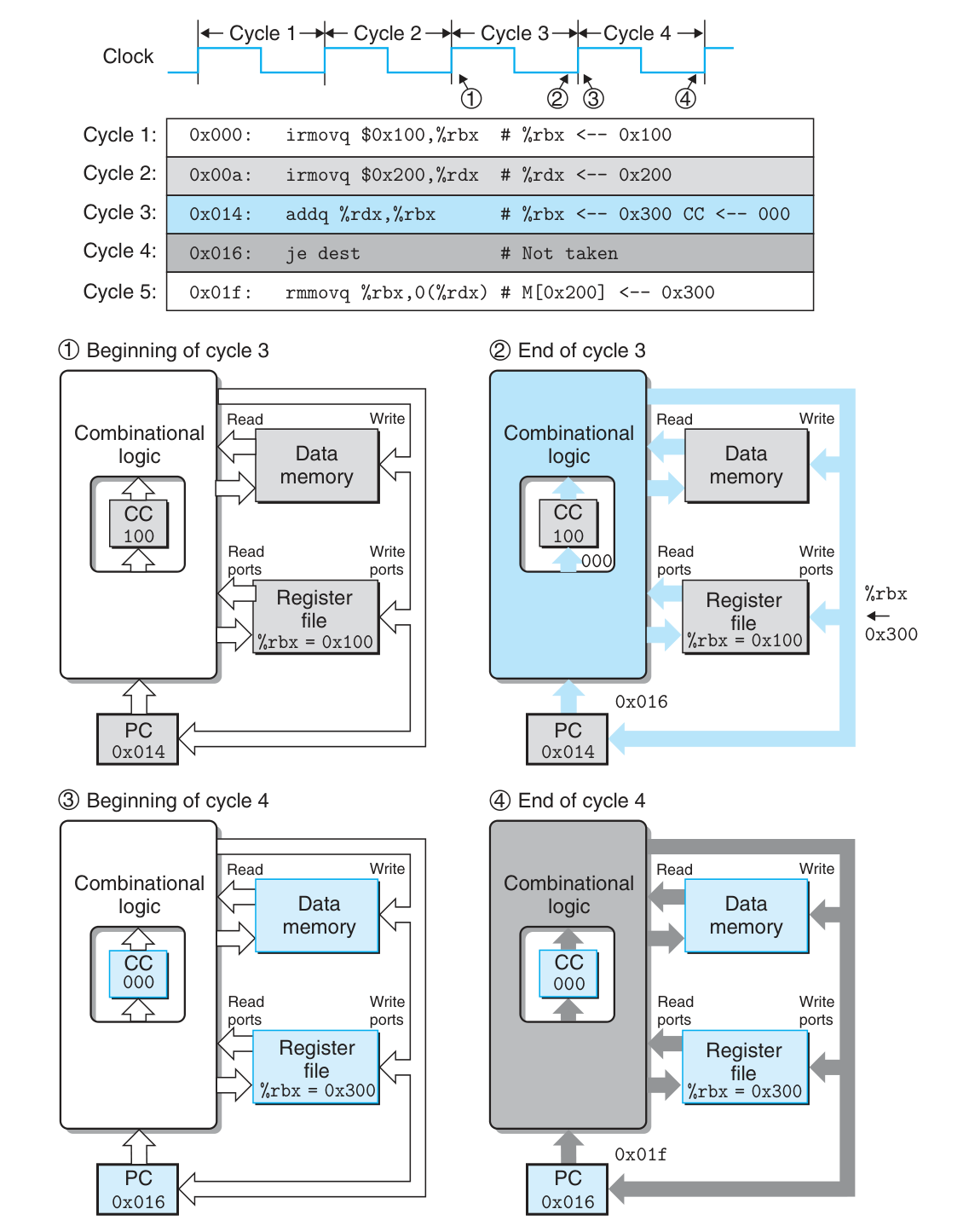
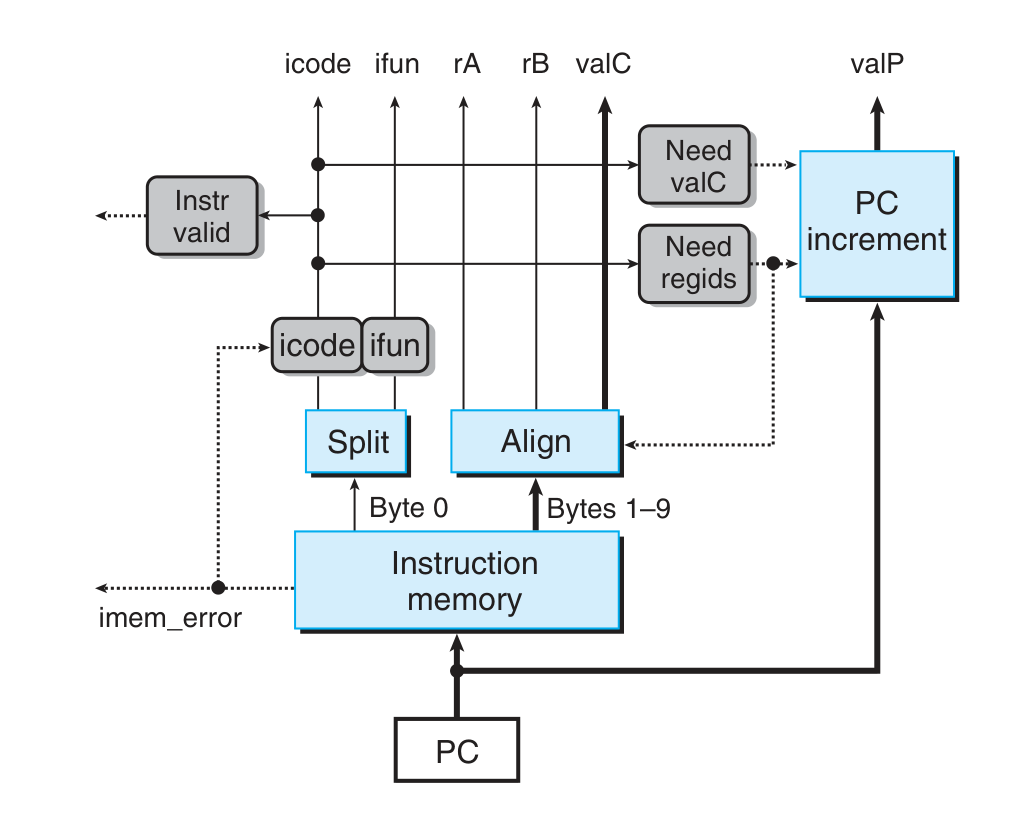
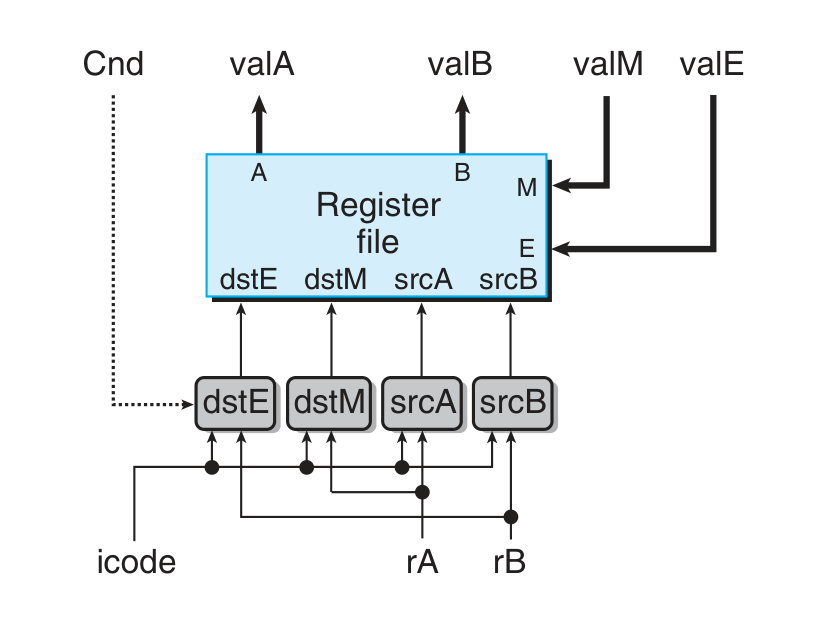
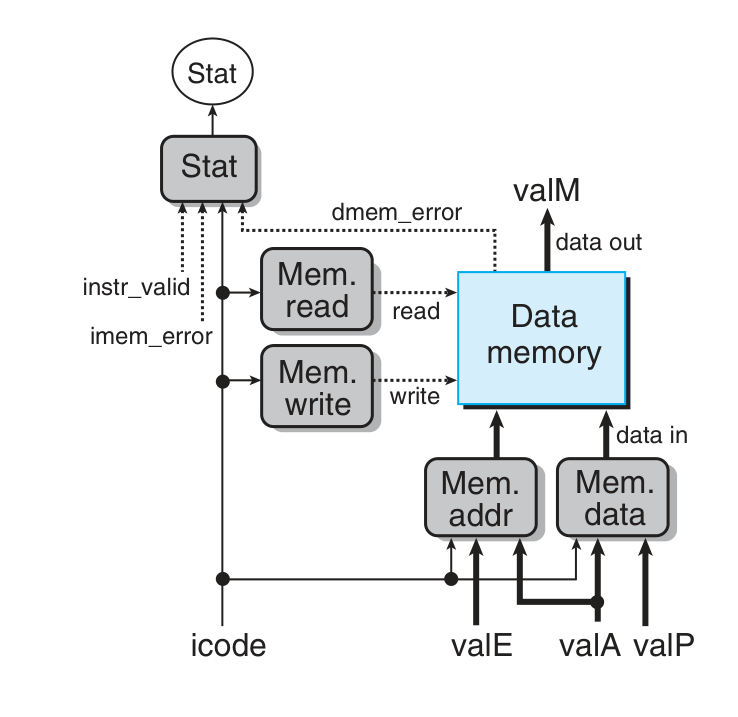
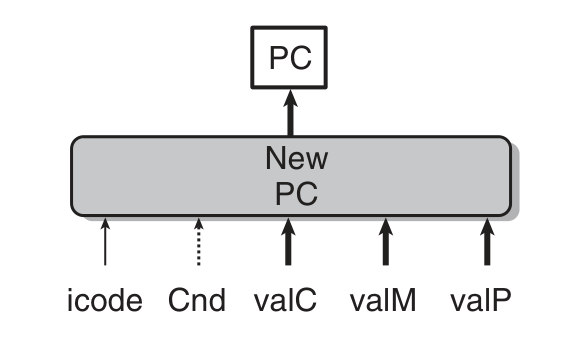
Pipeline
指令间独立、计算仅涉及组合逻辑的情况
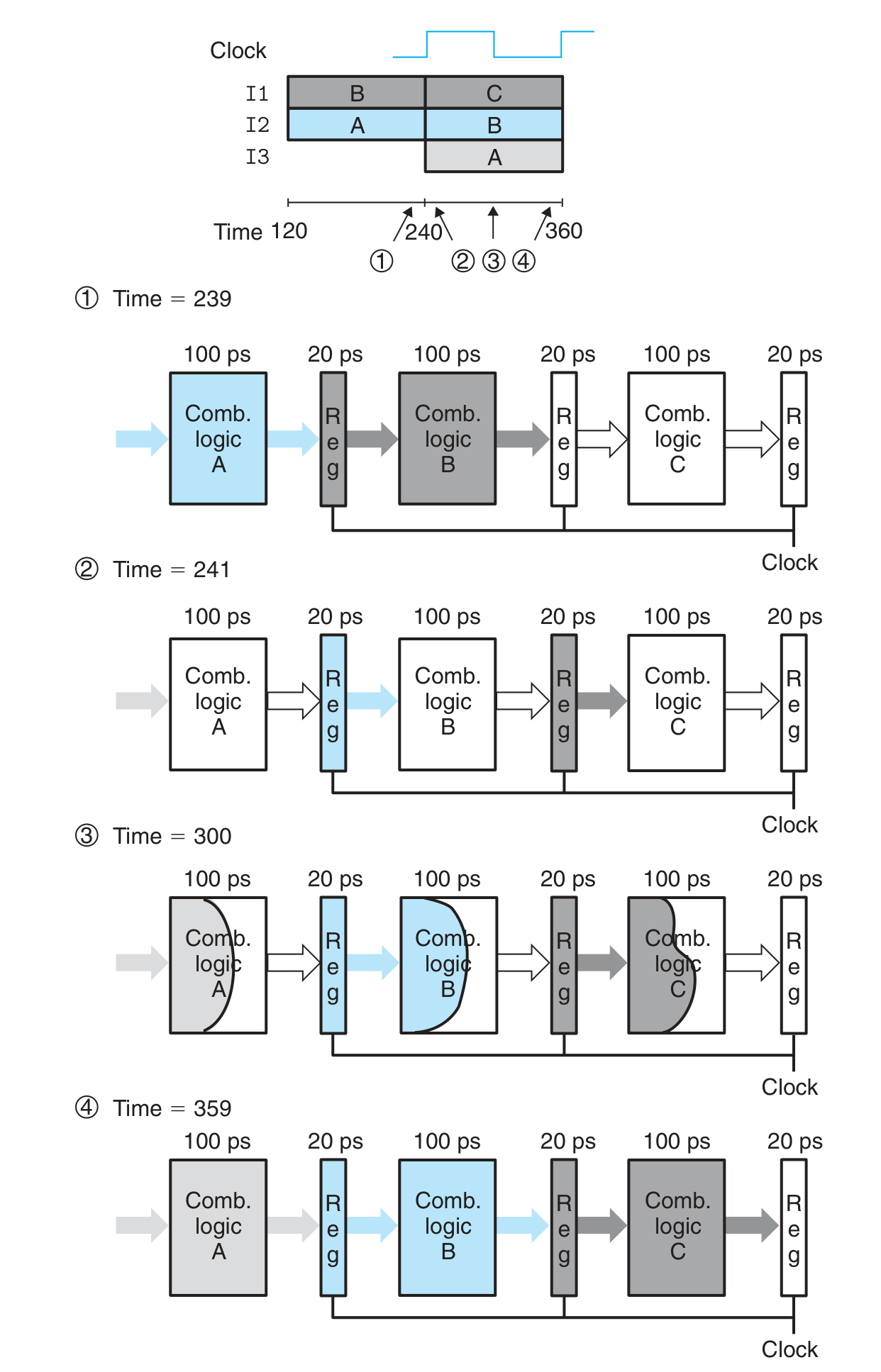
Limitation
Nonuniform Partitioning
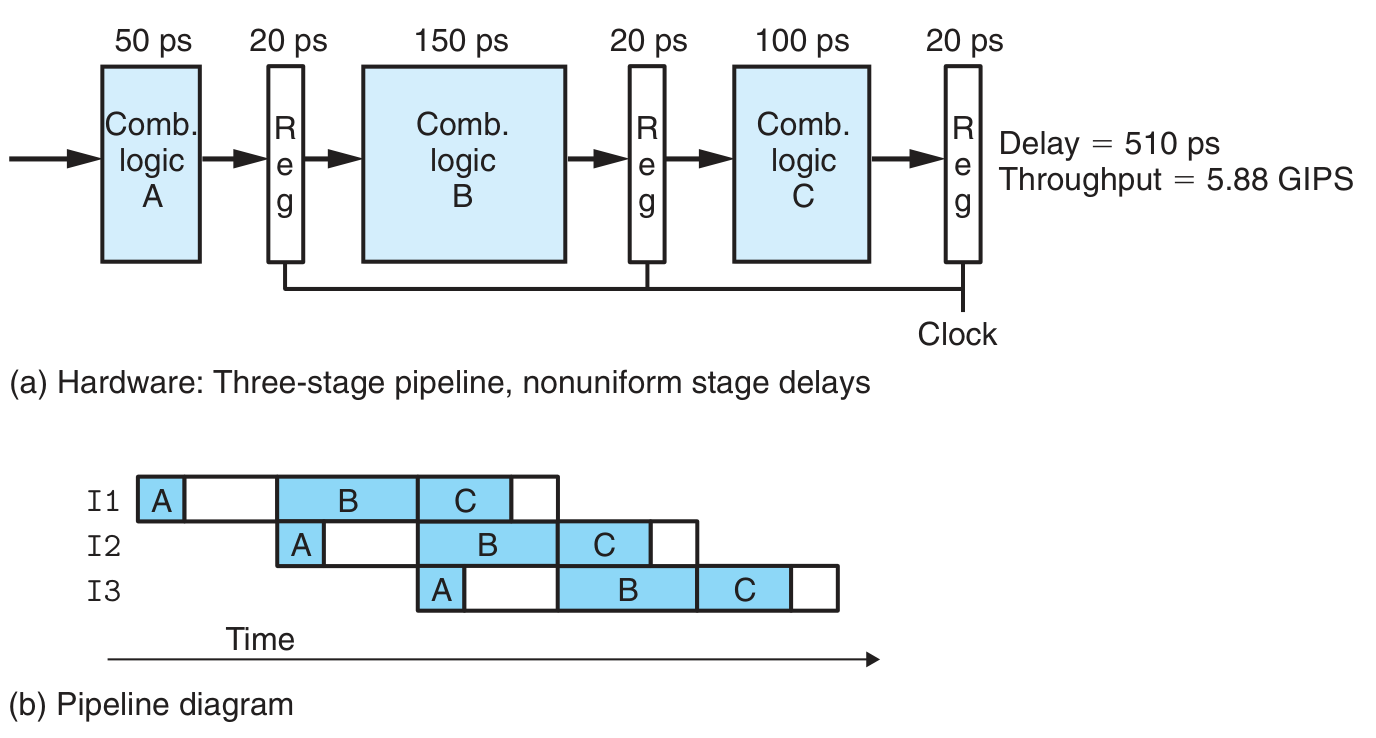
ALU 和内存常常难以切分
Diminishing Returns of Deep Pipelining
pipeline register 的 overhead 比重随切分次数的增加而增加
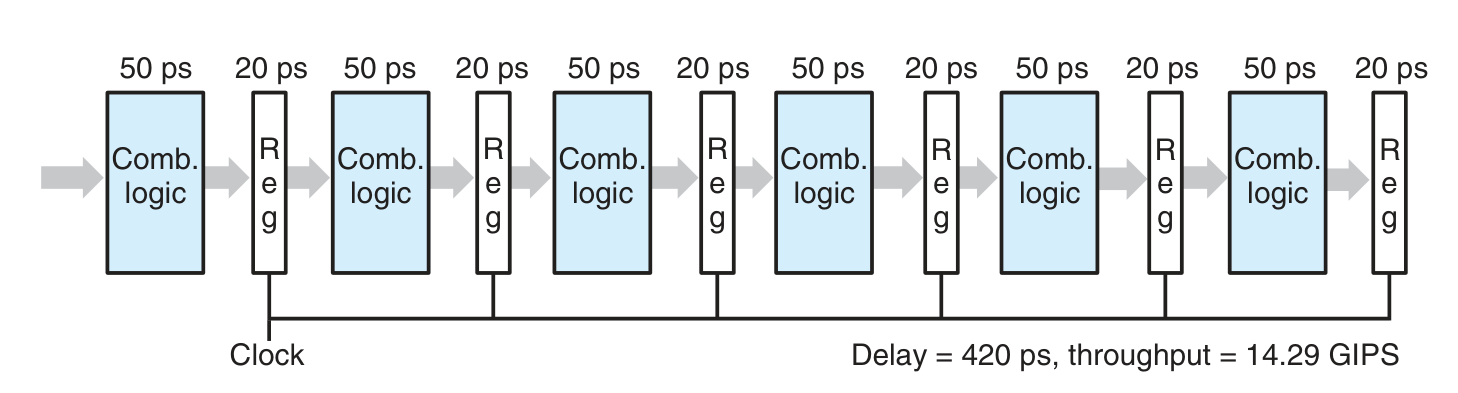
此例中 Throughput = 1 / (300 / k + 20), Latency = 20 * k + 300
Stage Implementation and Pipeline Control Logic
需要实现两部分逻辑:pipeline register 之间的转换逻辑和 pipeline register 的控制逻辑。这两种逻辑共同服务于
-
类似 SEQ 的基本指令要求;从结果上保持指令执行的顺序
-
解决 Data dependency 的 forwarding 和 stall/bubble 机制
-
解决 Control dependency 的 branch prediction 机制,特别是 mispredict 和 return 部分
-
处理 Exception
- 期望达到效果:之前的指令全部完整执行,此后的指令不会修改 program-visible state,在异常指令达到 write back 阶段后停机
- 可以在 fetch / memory stage 检测到 exception,只有在 execute, memeory, write back 三个阶段可能修改 program-visible state。统一在 memory 阶段处理异常,如果在此阶段出现异常,需要阻止 execute 阶段对 condition code 的写入,并且通过在 memory register 添加 bubble 阻止 execute 阶段(以及之前阶段)的指令继续执行,最后当异常指令到达 write back 之后停机
阶段之间的转换逻辑除了满足类似 SEQ 的基本要求之外还要实现以下特性:
- Branch Prediction
- Forwarding
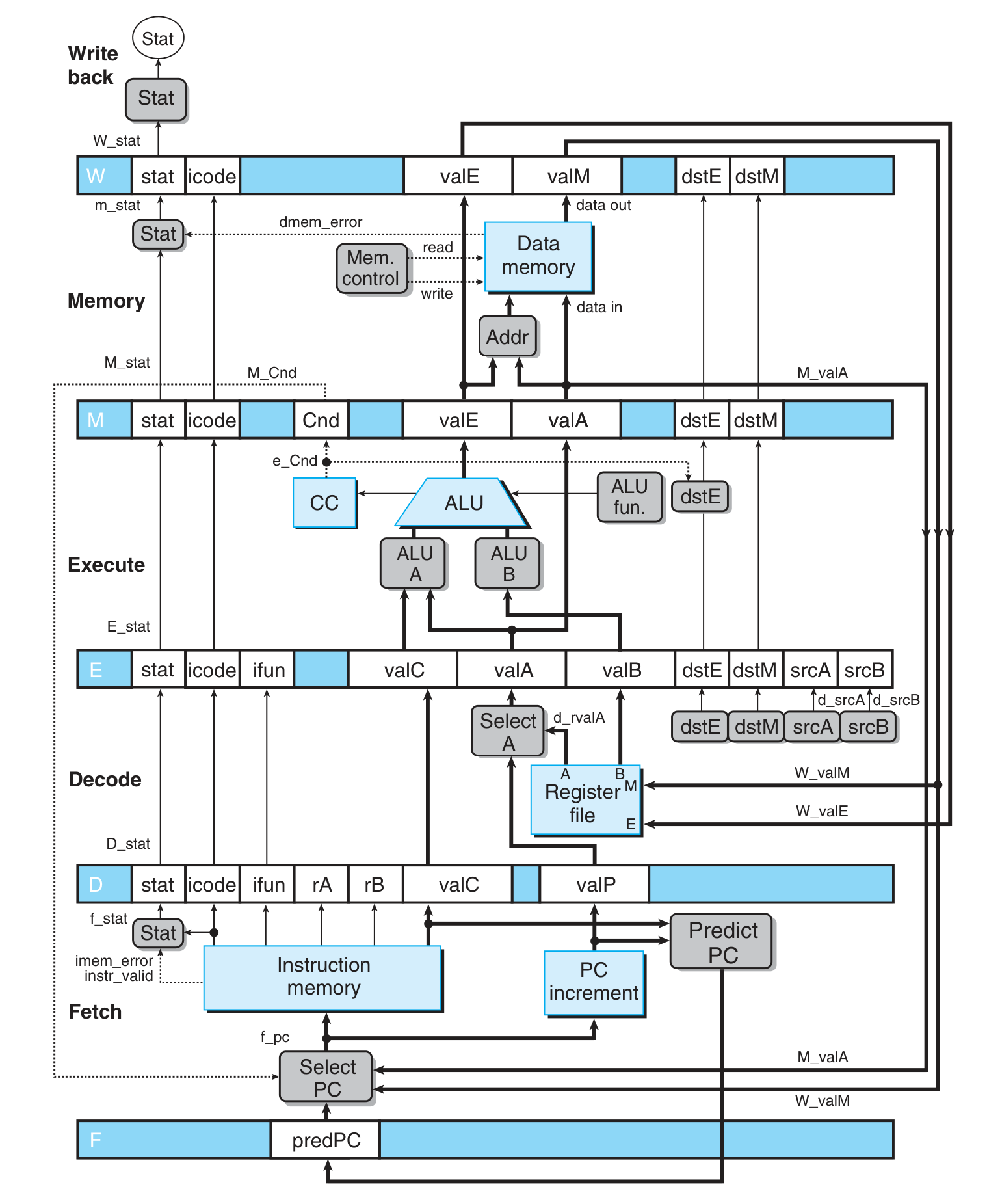
SEQ 添加 pipeline register 后
添加 forwarding 后
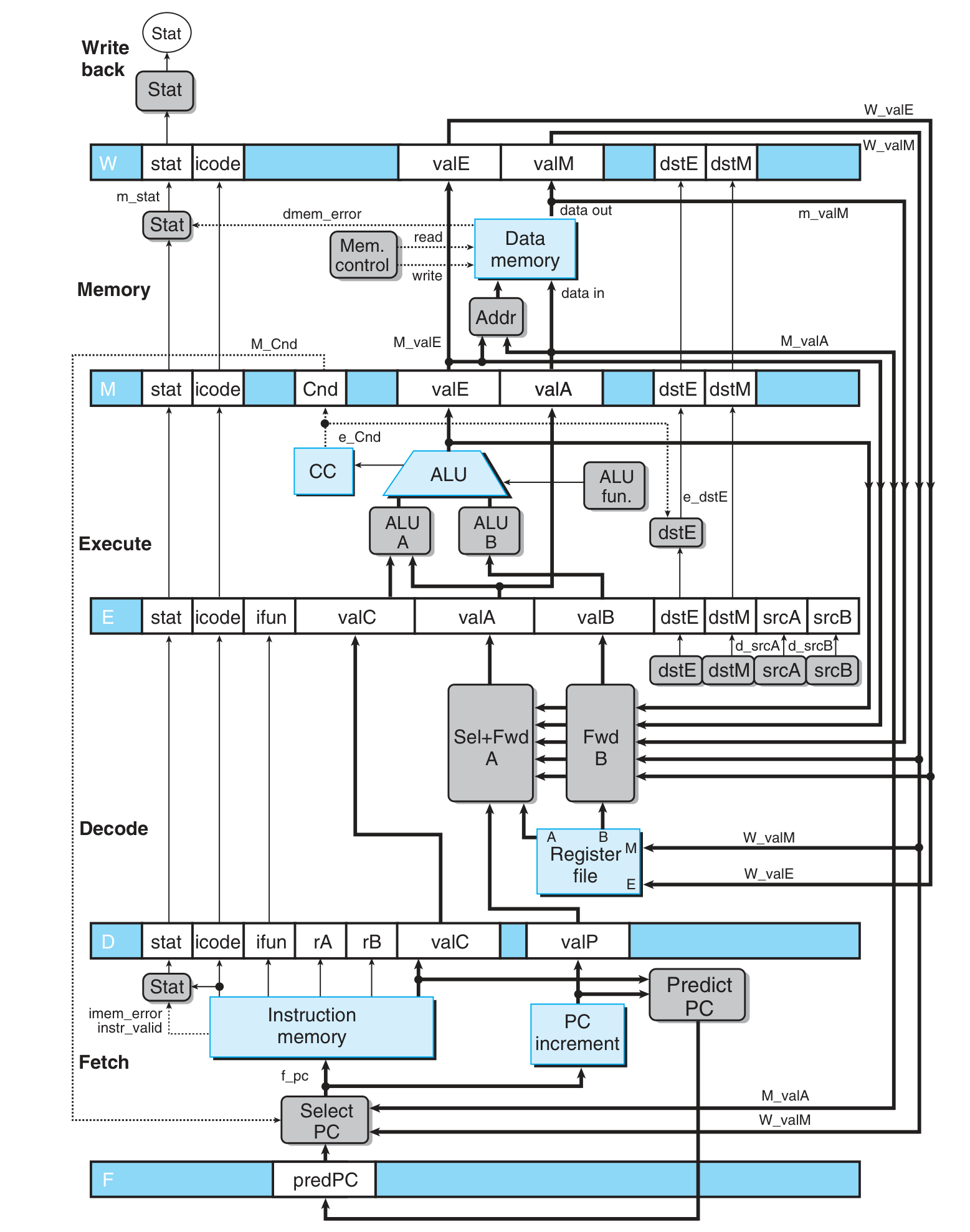
各阶段转换逻辑:
Fetch:
- select PC:
f_pc = { M_icode == IJXX && !M_Cnd: M_valA, # mispredict W_icode == IRET: W_valM, # return statement 1: F_predPC } - Predict PC:
f_predPC = { f_icode in {IJXX, ICALL}: f_valC, 1: f_PCincrement }
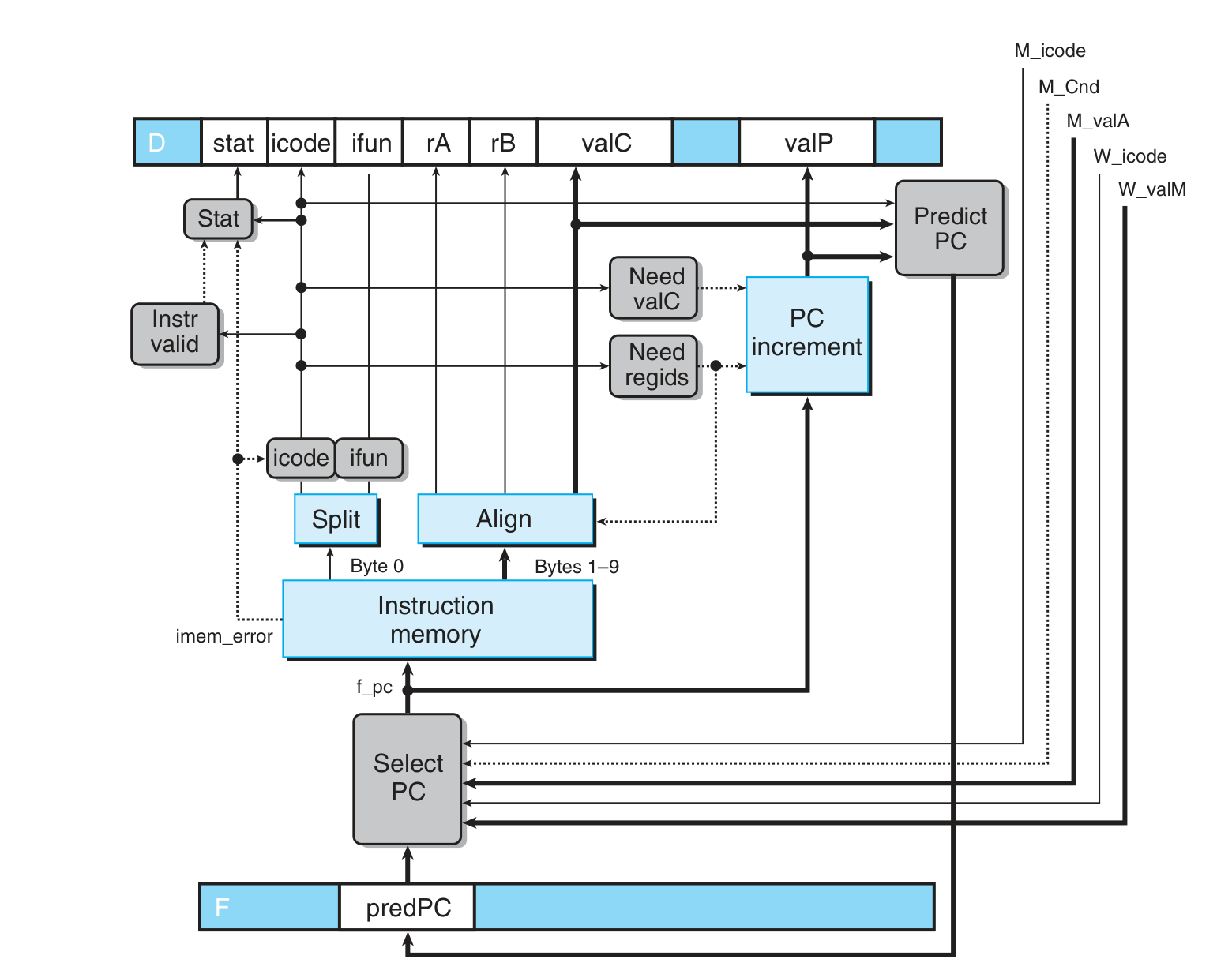
Decode:
注意 val A 和 val P 均被储存在 val A 处,因为它们不会被同时使用,共享同一个 word 可以节约内存
- Select + Forward A:
d_valA = { e_dstE }
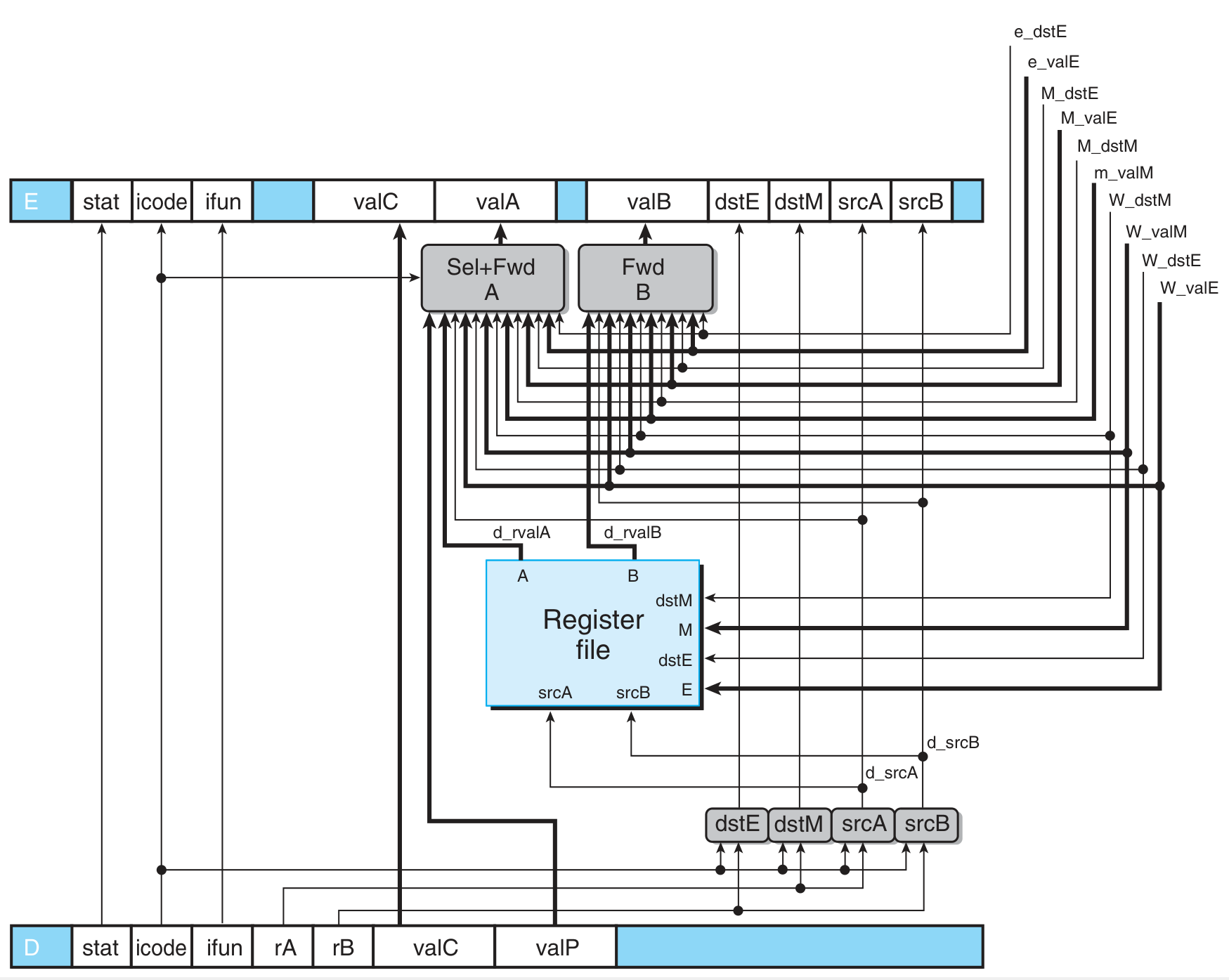
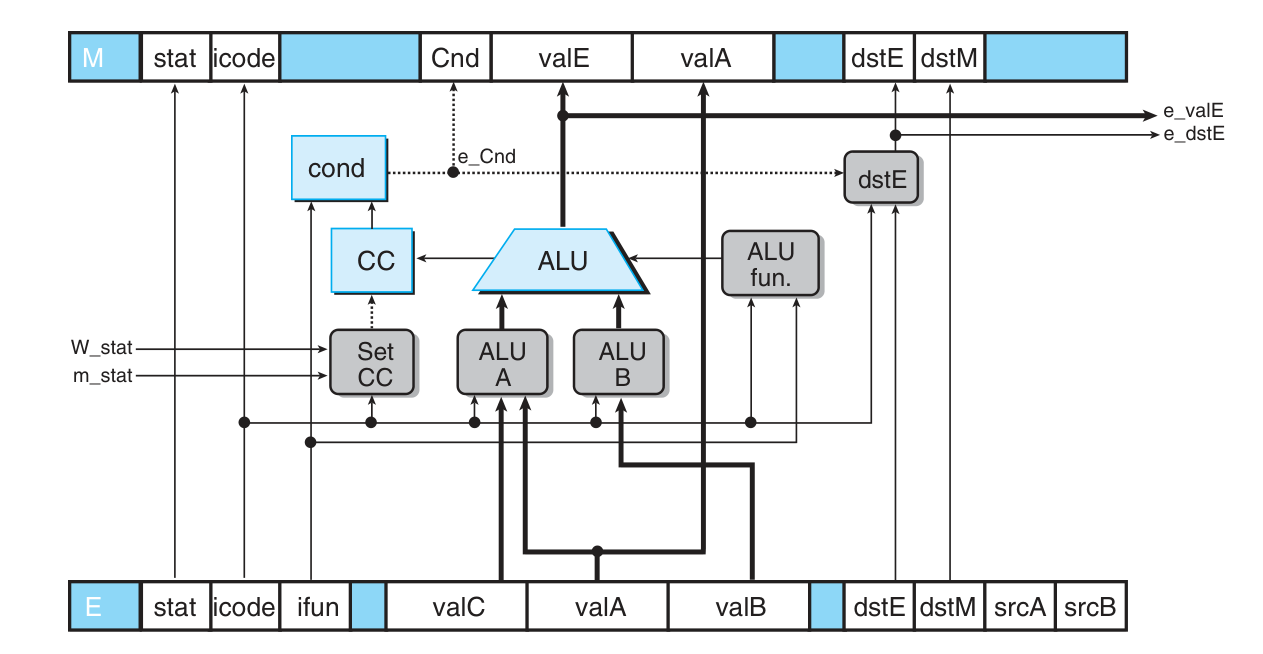
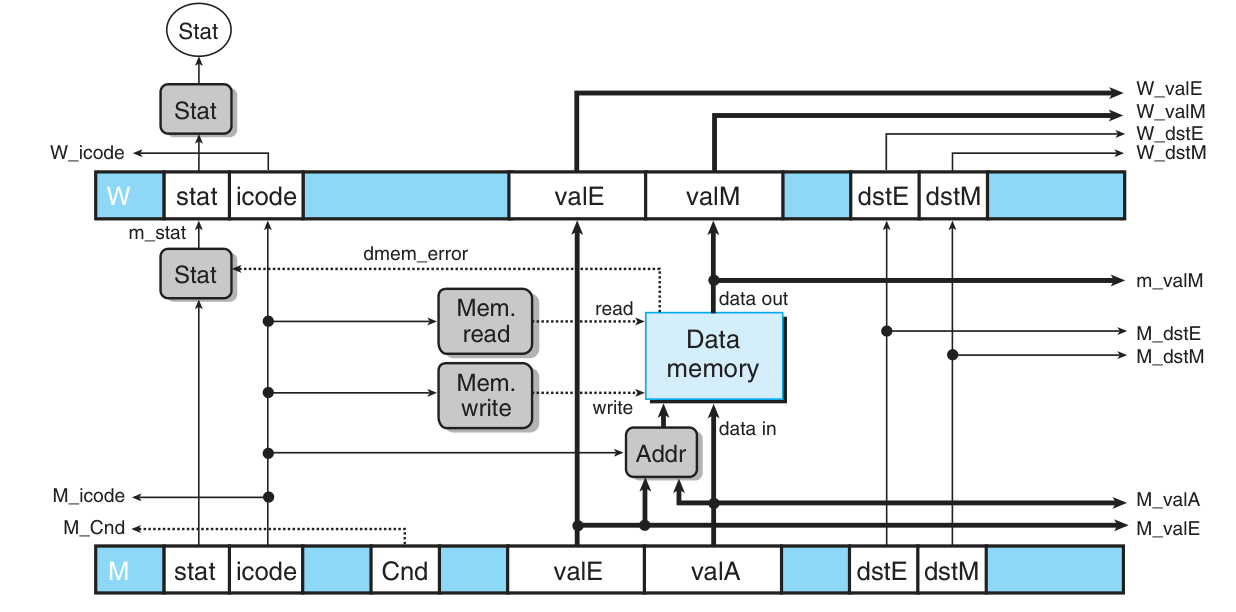
需要特殊控制流水线运转的情况(通过特殊的组合逻辑控制 stage register 的 stall 或者 bubble 接口,从而为下一周期的 pipeline register 状态提供优先级更高的额外控制。注意 F pipeline register 不能 bubble 否则会失去当前指令序列):
-
Exception:
- 触发条件:实际异常可在 fetch / memory stage 发生,但是集中在 memory stage 检测,在 write back 阶段也会触发是为了让异常指令恰好停止在 write bakc stage,
m_stat in {SADR, SINS, SHLT} || W_stat in {SADR, SINS, SHLT} - 期望达到效果:之前的指令全部完整执行,此后的指令不会修改 program-visible state,在异常指令达到 write back 阶段后停机
- pipeline control logic:
m_stat in {SADR, SINS, SHLT}:F D E whatever (since CC writing is suppressed), M bubble, W normal
W_stat in {SADR, SINS, SHLT}:F D E whatever, M bubble, W stall
- 触发条件:实际异常可在 fetch / memory stage 发生,但是集中在 memory stage 检测,在 write back 阶段也会触发是为了让异常指令恰好停止在 write bakc stage,
-
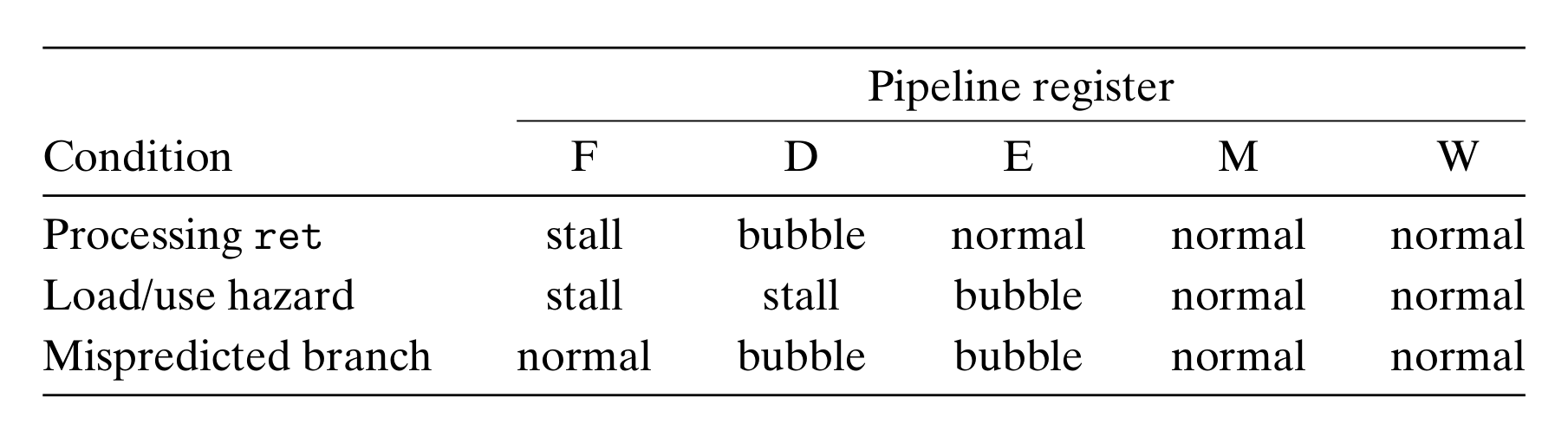
Load / Use hazard
- 大部分的数据依赖全都依靠 forwarding 几乎零开销地解决,不过有例外 mrmovq 和 popq 从 memory 读取数据并修改寄存器,当二者在 execute 阶段时是无法 forward 寄存器的期望值到 decode stage 的。stall 一个周期之后 forwarding 逻辑便可以正确处理
- 触发条件:
E_icode in {IMRMOVQ, IPOPQ} && E_dstM in {d_srcA, d_srcB} - pipeline control logic:F stall, D stall, E bubble, M normal, W normal
-
Return statement
- PIPE 不对返回语句进行任何预测,而是直接暂停三个周期。直到返回语句执行完 memory stage 时,才可以获得正确的 next PC。
- 触发条件:
IRET in {D_icode, E_icode, M_icode} - pipeline control logic:
- F_icode == IRET:F D E M W normal
- D_icode == IRET:F stall, D bubble, E M W normal
- E_icode == IRET:F stall, D E bubble, M W normal
- M_icode == IRET:F stall, D E M bubble, W normal
- 实际上,bubble 是可以在 D 到 W 之间传递的,考虑到这三种触发条件总是按顺序执行的,所以可以简化为 F stall, D bubble, E M W normal。
-
Mispredicted branch
- PIPE 默认预测条件跳转会跳转。在 execute stage 计算出 condition code 之后便获得了正确的 next PC,若与预测的不同需要清除前一条指令。
- 触发条件:
E_icode == IJXX && !e_Cnd - pipeline control logic: F whatever, D E bubble, M W normal
特殊情况的组合,仅有两种可能性:
-
原因:exception 十分特殊。return statement 由 ret + 0/1/2 something + intruction 组成, mispredicted branch 由 jxx + instruction 组成,load/use hazard 由 write + corresponding read 组成
-
jxx + ret:
- jxx in execute, ret in decode: F whatever(correct PC will selected as M_valA), D E bubble, M W normal
-
xrmovq xxx,%rsp + ret,此项组合处理具有考虑的必要性,否则会在 xrmovq in execute 阶段错误地将 D 同时设为 bubble 和 stall:
- xrmovq in execute, ret in decode: F D stall, E bubble, M W normal
- xrmovq in memory, ret in decode: F stall, D bubble, E M W normal
- xrmovq in writeback, ret in execute: F stall, D E bubble, M W normal
- ret in memory: F stall, D E M bubble, W normal
- overall: F D stall, E bubble, M W normal
补两张图用于查阅

Analysis
测试正确性、形式化验证正确性。
CPI 描述处理器架构的效率,他忽略了基础硬件响应速度带来的效率影响。
将 x86 64 与 PIPE 的指令对应,考察未实现的部分?
一些问题:
- 多周期指令:乘法除法浮点运算
- 处理器假设了内存写入读取可以在一个 cycle 内完成;内存虚拟地址要被转成物理地址;需要从硬盘读
PIPE 是一个简化的教学用处理器,他与现代处理器(如我的 13th intel core i9 13980HX)还有许多差距,在底层架构方面包括
- superscalar
- out of order execution
- hyper threading
- cache hierarchy
- more complicate branch prediction
- heterogeneous: multicore, integrated unit
- vectorization, SIMD