Chapter 6 Memory Hierarchy
Storage Technology
这一部分涉及过多硬件知识,没有那么有趣。而且,众所周知,硬件技术的迭代奇快无比,所以这一节内容都具有一定程度上的时效性。
- Different storage technologies have different price and performance trade-offs.
- DRAM and disk performance are lagging behind CPU performance.
Random Access Memory
Static RAM:6 transistor;稳定,由 bistable 元件实现;访问机制简单速度快。能耗与价格高
Dynamic RAM:1 capacitor + 1 transistor;不稳定,需要间歇性刷新;访问机制复杂速度慢。
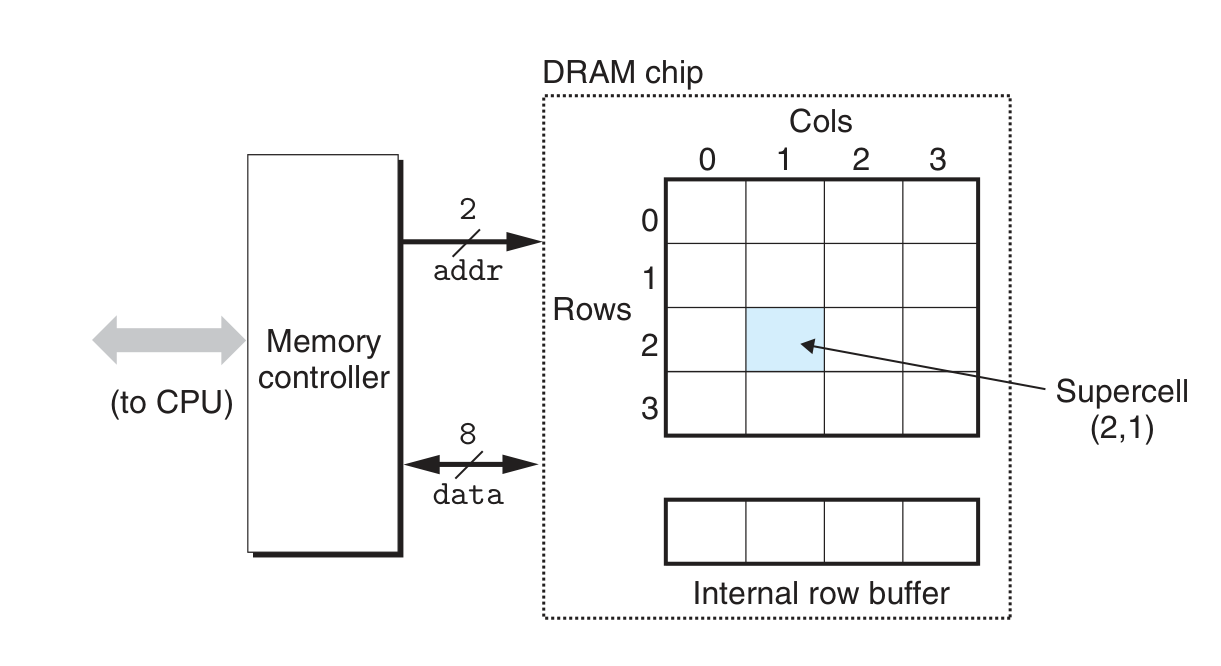
传统 DRAM 的单体、模组架构和访问机制
- 访问数据:addr 引脚通常较少,先传 RAS 再传 CAS
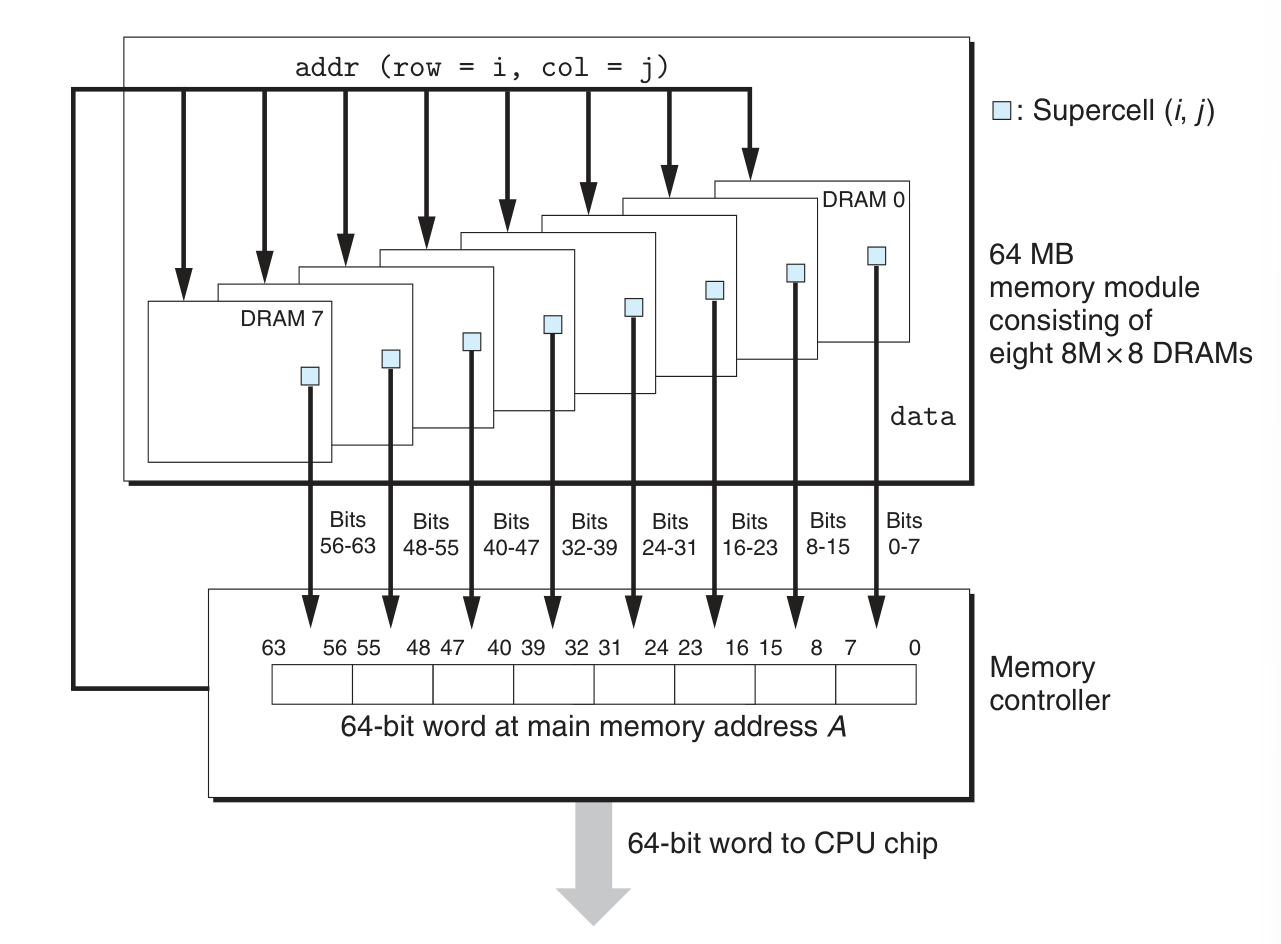
在下例中一个 8 bytes 数据被分为 8 份储存在 8 块 DRAM 构成的 modules 中
Fast page mode DRAM
Extended data out DRAM
Sychronous DRAM
Double Data Rate Synchronous DRAM
Video RAM
Non-volatile ROM
- prgrammable ROM
- erasable programmable ROM
- Flash memory
储存在 ROM 中的程序被称为 firmware
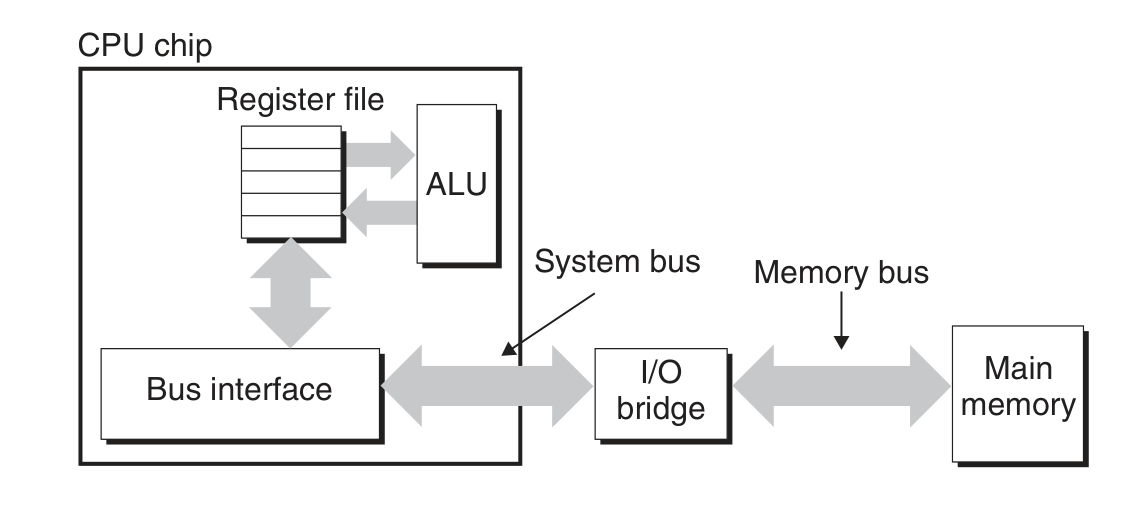
主存与 CPU 之间的数据交换路径,从指令出发的整个响应过程
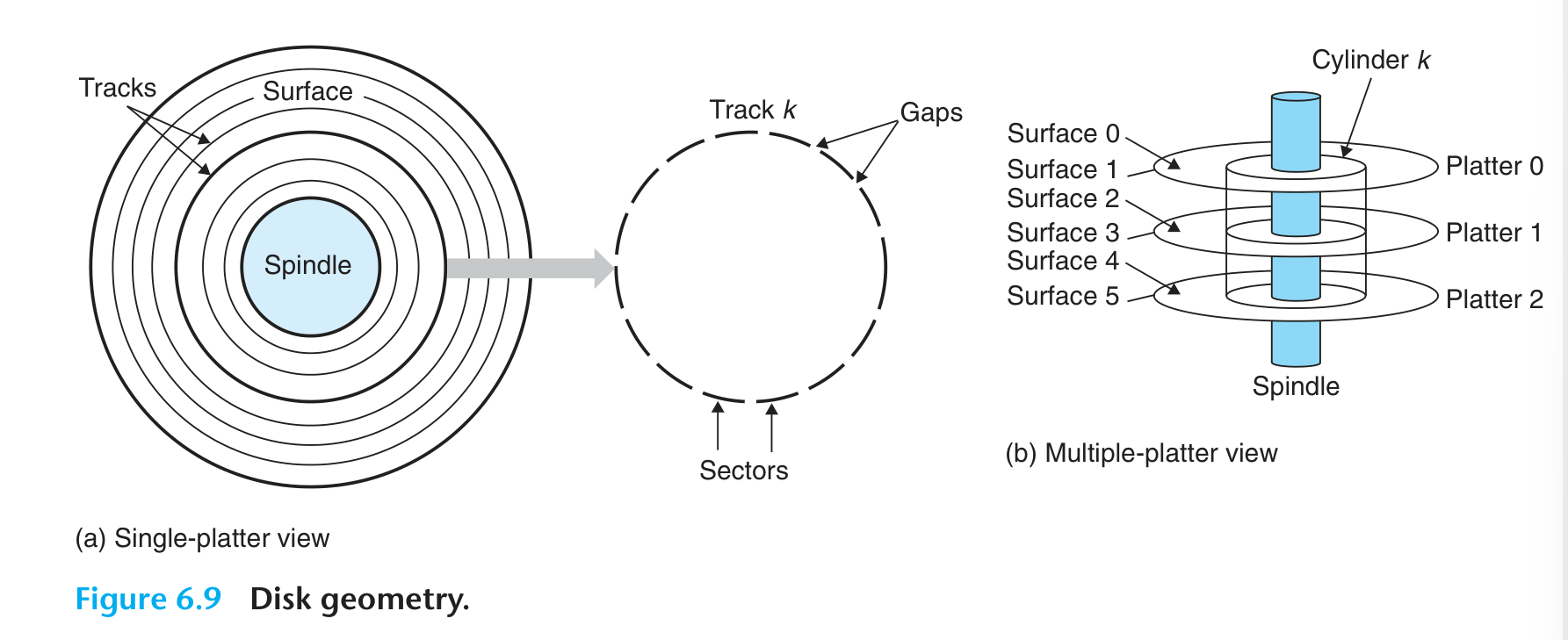
Disk Storage
结构
刻画容量

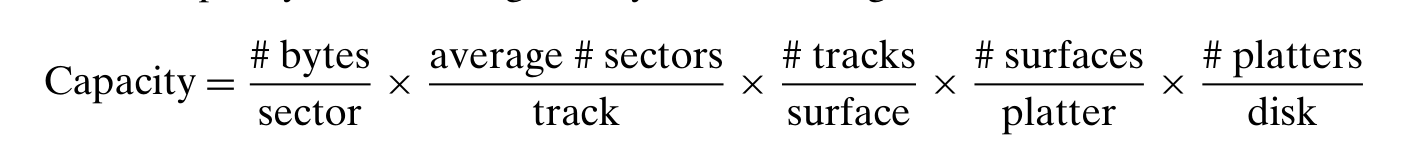
读写机制以及速度分析
- Logical Disk Blocks,由 disk controller 实现
- 机械动态
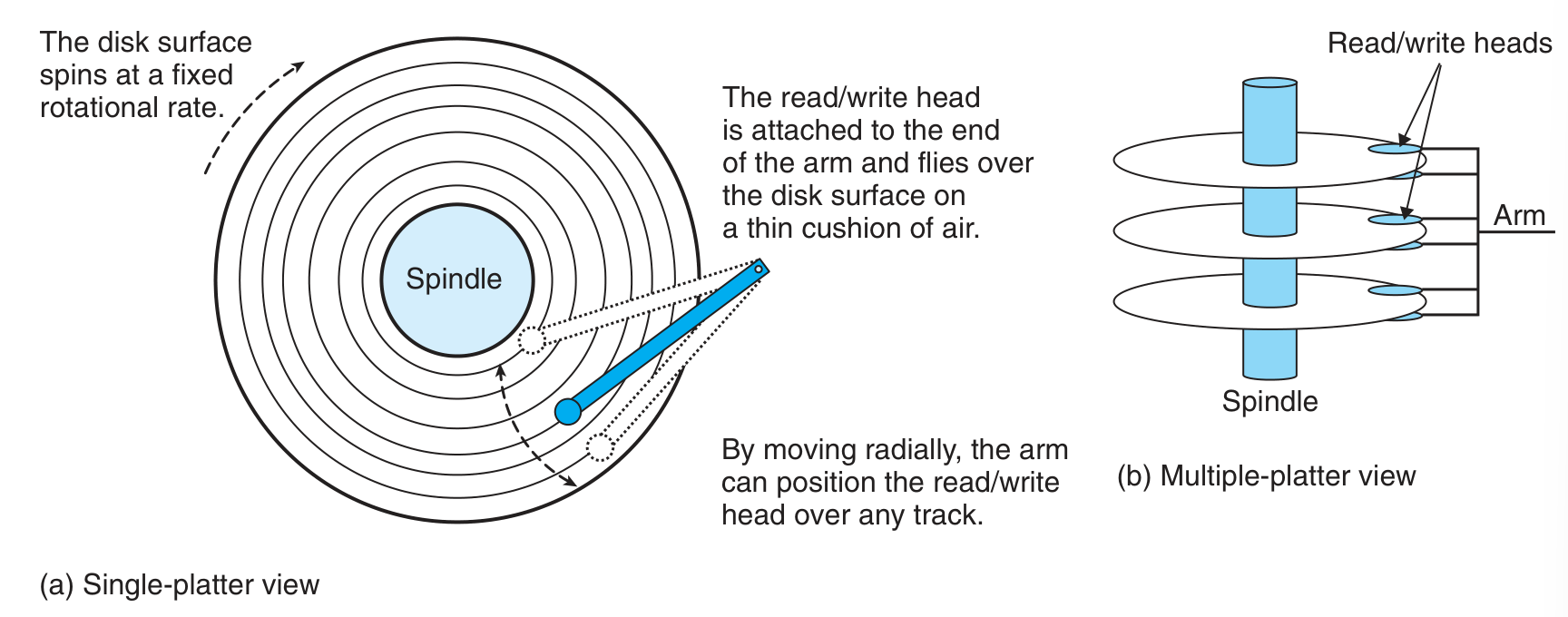
-
从 CPU 指令出发的整个响应过程(interupt,DMA)
书中此部分关于 I/O device 及接口的描述大部分已经过时
Solid State Disks
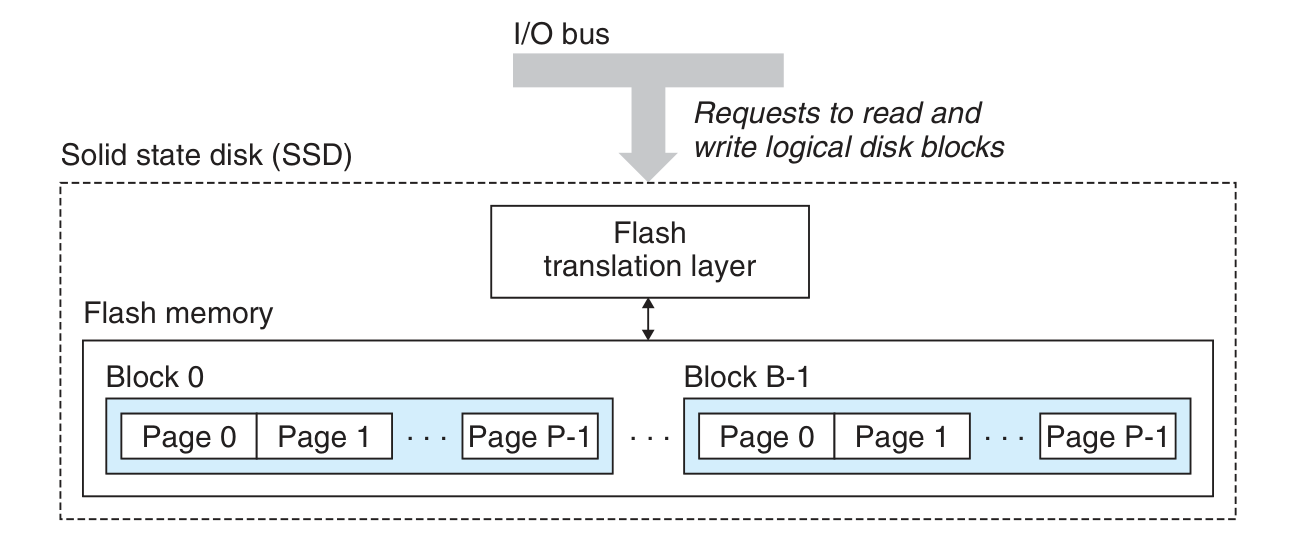
- 基于闪存,是半导体制品,速度通常比 Rotating Disks 快很多
- Flash translation layer 提供 Logical blocks,并合理分配数据使得写入速度变快、各 blocks 磨损均衡
- 写入限制:A page can be written only after the entire block to which it belongs has been erased
- 会磨损,寿命有限
Locality and Memory Hierarchy
Temporal locality
Spatial locality
data/instruction locality
stride-k data reference pattern
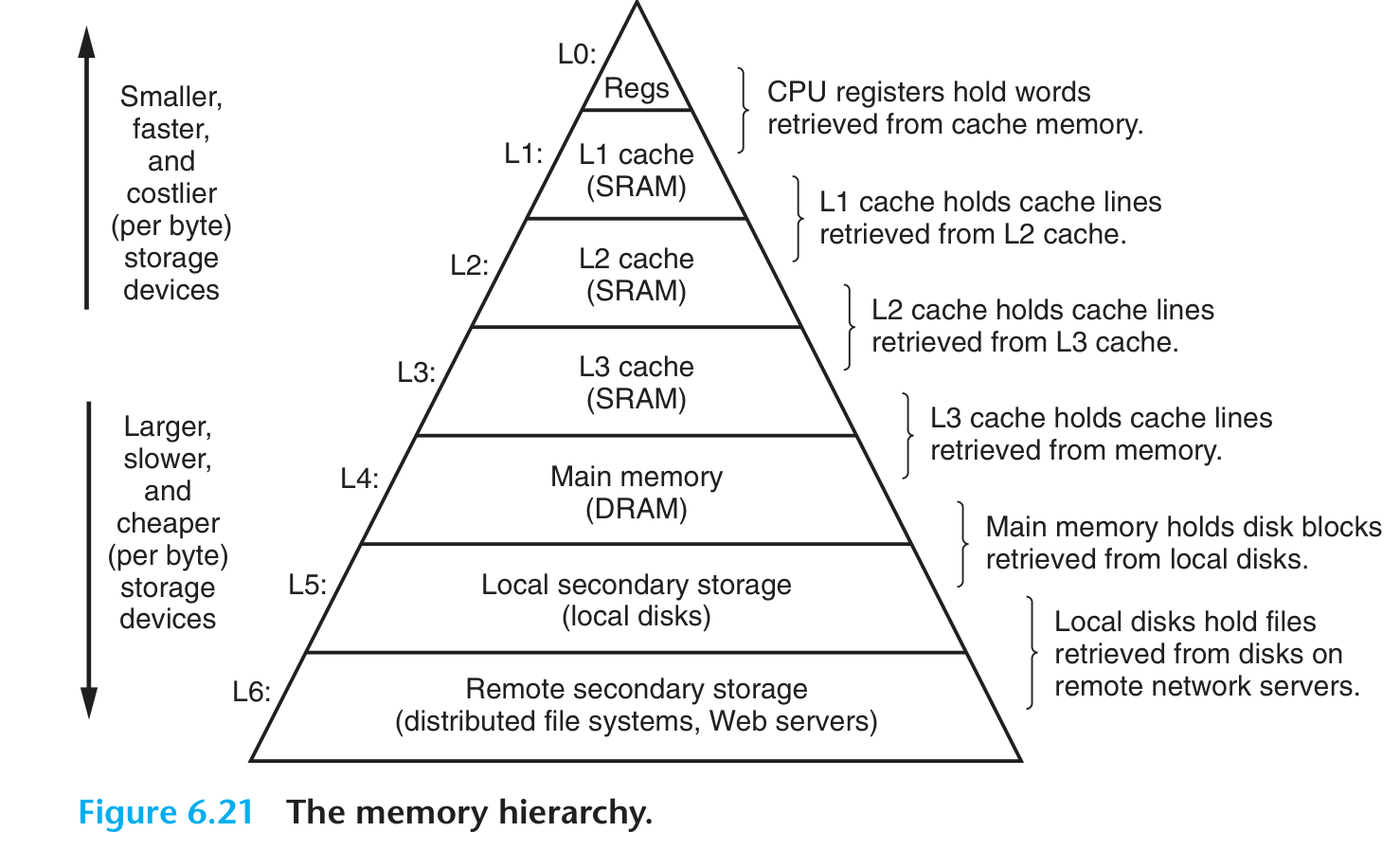
cache hit
cache miss
- block replacement policy: random, least recently used(LRU), mod
- compulsory / cold miss, conflict miss(especially in mod rep policy), capacity miss

以 regiseter L1-Cache Main Memory 架构中 L1-Cache 结构为例
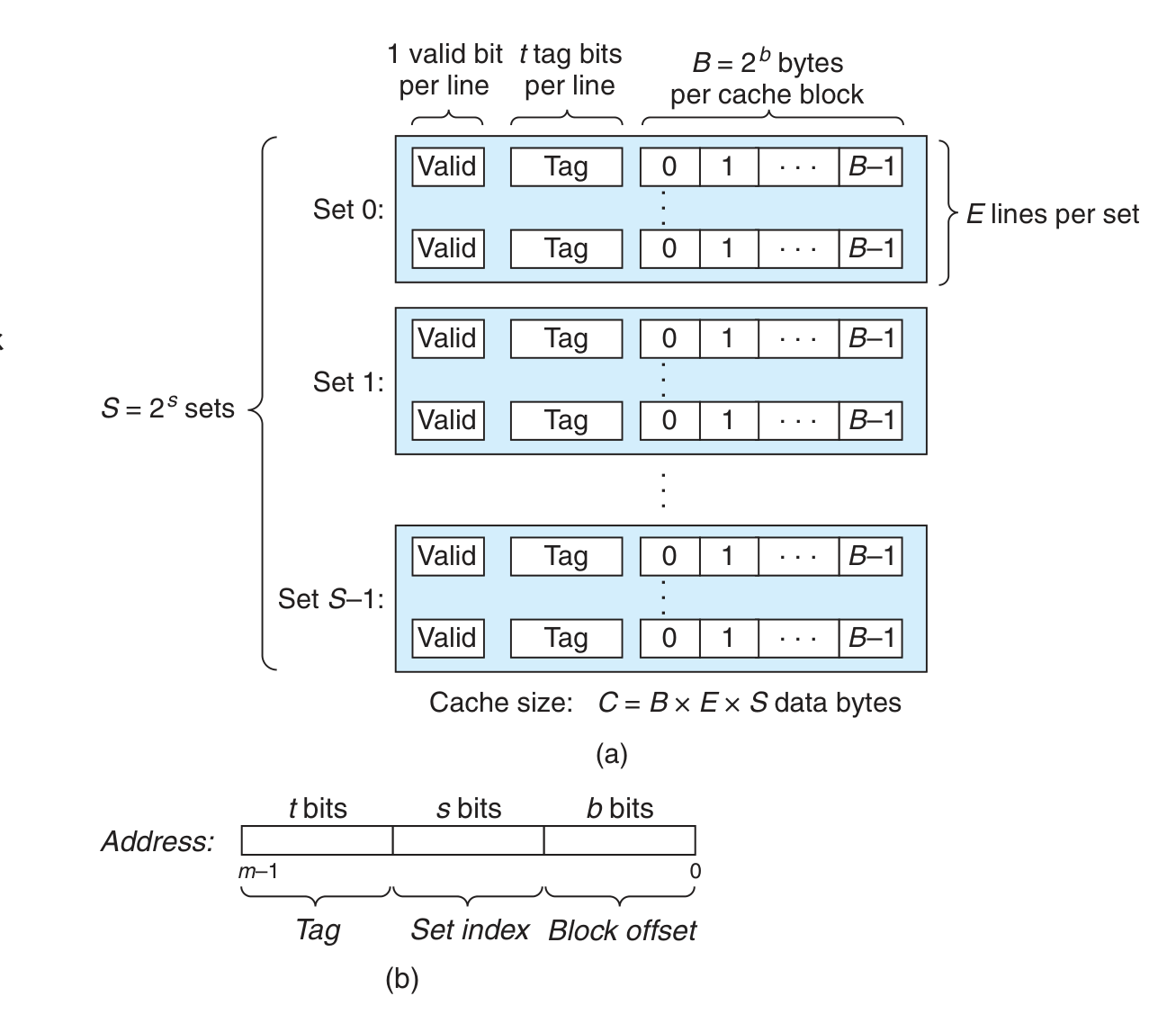
Cache 的实际容量为
由于以 block 为单位进行处理,转换为 cache capacity = S * E blocks,data amount =
按地址的 s 个 bits (最低 b 个已经用于组成 block)对 block 进行分组,使一个 block 只能储存在特定的 set 中,每个 set 可能包含的 block 有
为什么 set index 是中间的 b 个连续 bits?
- 不能是尾因为数据以 block 为单位在 cache 之间传输
- 不能是首否则一长段的连续地址(通常超过程序长度)只能使用一个 set
- 不分散是为了方便处理
data access 步骤:set selection, line matching(valid bit and tag checking, if miss then replace/add), word extraction
Direct-mapped cache:E = 1,容易因为 same set mapping 导致 confict miss,可以通过 padding 一个 block 错开 set mapping
Set Associative Caches:1 < E < C / B,每个 set 有类似 associative memory 的访问操作形式,底层机制是遍历。Line replacement policy(miss and cache full):random, LFU...
Fully Associative Cache:S = 1, E = C / B,只适用于 small capacity cache,如 TLBs
write hit:write-through;write-back,需要对每个 cache line 维护一个 dirty bit
write miss:no-write-allocate;write-allocate,exploit write spatial locality
i-cache d-cache unified-cache
- for a program instruction flow and data flow are separate
- a instruction evicted becauze of conflict miss
miss/hit rate, hit time(order of several cycles for L1), miss penalty(order of 10 cycles for L1)
- C
:hit rate ,hit time(due to overhead) - B
:hit rate ,hit rate(given fixed cache size, due to reduced cache lines) ,miss penalty - E
:vulnerability for conflict miss ,hit time(due to overhead) 。 - Write strategy
Lower cache(huge miss penalty and write infrequency):C,E ,write-back/write-allocate